
|
|
Clumpy Heapsortversion 0.2 |
What if you laid out a heapsort heap differently to improve locality of reference, so that as the sort walks down the heap, it accesses sets of locations that are close together rather than scattered, in the hope of running faster by making more of its accesses in cached memory?
The original Williams/Floyd heap (what's called "Vanilla" here) looks like this:
1
2 3
4 5 6 7
8 9 10 11 12 13 14 15
...
Here the left and right children of node n are nodes 2n and 2n+1. At
each level of the tree, the distance between children and parents doubles.
Suppose instead we arrange a tree like this:
1
2 3
4 7 10 13
5 6 8 9 11 12 14 15
/ \_________________
16 31
17 18 32 33
19 22 25 28 33
20 21 23 24 26 27 29 30 34 35 ...
This builds "clumps" of three, then clumps of 15 out of clumps of 3,
then clumps of 15 * 17 = 255, then 65535, etc. Every other step down
the tree is a distance of 1 or 2; three out of four steps are < 10,
7/8 of steps are <= 240, and so forth. So this layout has
better locality of reference, although the relation between
the parent and child node addresses is less simple than in the Vanilla heap.
Another difference with a heap arranged this way is that it can become more unbalanced than a Vanilla heap, for which the lowest nodes are different by at most one level of depth. With the Clumpy tree, once a tree of, e.g., 15 elements and a depth of 4 is built, a depth 4 subtree is constructed next. In the diagram above, you can see that a tree of 29 nodes would have a depth of 8 in seven of its leaves (20, 21, 23... 29) and 4 in the other seven (6, 8, 9 ... 15). Similar imbalance happens just after trees of 255 and 65535 nodes become filled.
I tested the effect of Clumpy and other arrangements by writing a C program that heapsorts arrays of random 32-bit numbers, with different formulas plugged in (with #ifdefs) to set the memory layout. A bash script runs the test over the different variations of the program, and a Python program takes the results and produces the graph below, using the ReportLab pdfgen library. I should stress that this is a test with just one record size (four bytes), one computer (a 700MHz PPC G3), one cache configuration (256K of level-2) and one configuration of memory (768 MB).
(Click for the pdf.)Rough Analysis
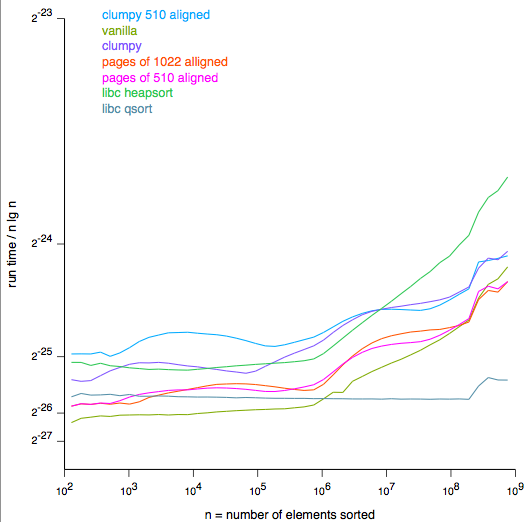
As has been pointed out by others who have worked on "cache-friendly," "cache- obvlivious," and disk-based heapsorts, improving the locality of reference of a heapsort might improve efficiency by at most O(lg n), while cache lines, pages sizes and access times grow with the amount of memory accessed, and so although this test shows some modified heapsorts running up to twice as fast as Vanilla heapsort, this approach will never be a big win.
The horizontal axis of the graph is the log of the number of elements of the set to be sorted. The theoretical time complexity of heapsort, assuming all memory accesses take the same time, is O( n lg n ). The vertical axis shows the linear ratio of the actual time taken to the theoretical time. So, for example, the green Vanilla curve runs nearly flat for two and a half orders of magnitude of n and then starts getting slower.
There are two important points on the x axis. At 65536 entries (which for 32-bit numbers means 256K bytes) two things happen. First, the level-2 cache of this particular computer fills up. Second, the Clumpy arrangement hits one of the places (65535 nodes) where the tree balances perfectly.
What happens roughly for all the variations, is that some top part of the heap-- around 16 levels-- tends to stay within level-2 cache because access frequency is higher toward the root of the tree. Then, as the problem size gets larger, paths down the tree spend more and more of their time accessing the slower main memory. Since the total depth of the tree is O( lg n ), the fraction of a path in slower memory is O( ((lg n) - 16) / lg n ). At first this grows like (lg n)-16, which explains the nearly linear second half of the Vanilla curve (with the horizontal axis a log). Eventually, with many gigabytes of memory, the slowdown would level out. But main memory is many times slower than level-2 cache. The clearest measure of that is that Vanilla slows down by a factor of five (compared to O(n lg n)) with hardly a sign of flattening out.
The second important point is the right edge of the graph. At 2^27 entries or about 512MB, the real memory is almost full. Doubling the problem size makes the program start swapping virtual memory pages, and the performance goes down so badly I haven't had computer time to run the test. Sorts like the "external heapsort", which merge sorted blocks in a heap arrangement, make much better use of slow-to-access memory.
The code to calculate the Clumpy parent-child address relationship involves five cases, and multiple multiplication, division and modulo operations. So Clumpy starts out about 100 times slower than the Vanilla heapsort. It hits one sweet spot at 255 entries, and another at 65535, and then slowly catches up with and overtakes Vanilla heapsort.
A few other arrangements tested are shown in the graph:
Pages of 1022 aligned groups the array into pages of 1024 entries, of which 1023 are used on the first page and 1022 on every subsequent page. The first page is a Vanilla heap, and every subsequent page is a heap with the top node removed, so that the first two nodes are sibling children (at locations 2 and 3 within the page) of a parent node on an earlier page. The reason is that heapsort always accesses both children of every node on a path down the tree, and if pages started with a single node instead of a pair, pairs of pages would need to be fetched instead of single pages. The word "aligned" refers to this arrangement starting with two siblings, and all sibling pairs on even boundaries.
However, memory areas the size of a page aren't really relevant to level-2 cache. The main advantage of this method over Clumpy is that it is simpler to calculate the parent-child address relationship.
Pages of 510 aligned This is similar to Pages of 1022, with pages of half the size and one less level of depth.
Clumpy 510a This is like Pages of 510 aligned, but within the pages there is a modified clumpy arrangement:
(1)
2 3
4 5 6 7
8 9 14 15
10 11 12 13 16 17 18 19 ...
The (1) node is only used on the first page of the array.
This is supposed to improve Clumpy's locality by always putting
siblings together and on an even boundary. This method has
calculation complexity between that of Clumpy and Pages of 510.
Clumpy 510a has a sweet spot at 511, and a lesser one at 130,816,
which matches a slight sweet spot for Pages of 510.
I haven't tested the paired-sibling arrangement in a non-paged Clumpy.
Why do Clumpy and Clumpy 510a finally flatten out more than Pages of 1022 and Pages of 510? Probably even while chewing into uncached memory, the Clumpies do multiple accesses to the same cache lines on the way down a path, more often than the Pages methods do. Also, Clumpy is coming out of one of its unbalanced- tree phases, which are worse than the imbalances of the three paged methods, so it's not so much getting better as getting less worse.
It's not clear whether any of these arrangements take advantage of the level-1 cache in a way that isn't spoiled by the additional code complexity inside the inner loop. The child- address calculation could be unrolled to remove the case statements and reuse the results of some calculations between levels of the tree...but I haven't tried that.
Makefile (2K) |
compile code, create index.html, run tests with 'make test', then 'make graph.pdf' |
an_eqn.c (3K) |
solves some linear equations to get constants in clumpy code |
cache_friend.c (14K) |
source for #ifdef'ed variations of heapsort |
cache_friends_plot.py (11K) |
generates PDF graph from test ouput files, easiest to run with 'make graph.pdf' |
cache_friends_test (1K) |
test loop run by Makefile |
clumpy_sequence.py (3K) |
generate the clumpy index sequence for OEIS A082008. |
graph.pdf (8K) |
PDF version of the graph above |
graph.png (46K) |
PNG graph image shown above |
solveqn.c (2K) |
linear equation solver |
This page was made with a
php script.
Last change January 28, 2021 17:32:36 EST.
--Steve Witham
Up to my home page.