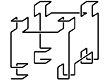
|
|
Hilbert Curves in More (or fewer) than Two Dimensionsversion 0.6.5 |
Let's develop Python functions to map between a point on a Hilbert walk in D dimensions, and an integer we'll call the index of the point, so that, e.g.,
int_to_Hilbert( i, 3 ) ==> ( x, y, z ) Hilbert_to_int( ( x, y, z ) ) ==> iHere ( x, y, z ) is a Python tuple. There's an appendix on some Python details below.
[Wikipedia] shows code for the two-dimensional mapping. [Butz] and later [Lawder], [Moore], [Thomas] and [Jaffer] show algorithms and code that extend Hilbert's curve beyond two dimensions; here I try to explain one unoptimized method simply.
We don't require the caller to specify the number of bits of precision. Instead, our functions accept either Python's "int," or arbitrary-precision "long" arguments, and determine the precision from the arguments themselves. (For the most part, the difference between int and long is handled automatically in Python and invisible in the code.) Results for large and small numbers need to be made consistent, though.
3---2
|
0---1
the first step is along the x axis, but we'll say the walk
as a whole travels along the y axis.
"Travel," here, means the difference between
the beginning and end of the walk of a cube (here a 2-cube).
When D>1, the travel of a unit D-cube walk is always along a different
axis than its first step.
. . 5---6 9---10 | | | | 4 7###8 11 # # 3---2 13--12 . | | --0---1...14--15--> ... |The 2D Hilbert curve is defined recursively so that a large walk is composed of four smaller Hilbert walks. The obvious extension is to build a large parent D-cube out of 2D subcubes or child cubes. Although there are extra steps (marked "#" above) between the children, all of the stops on the walk are stops within children.
If the coordinates of the points are expressed in binary, and the bottom left corner of the parent is (0, 0, ... 0), then the most- significant bits of the coordinates are walked in a a unit cube walk. In fact, the D most significant bits of a point's index are transformed by a modified Gray code to become one most- significant bit of each of its D coordinates. The children consume less- significant bits of index and control less- significant bits of the coordinates.
This method is neither particularly beautiful nor ugly, but works the same way for any number of dimensions. (I found it while trying to understand [Jaffer] below-- the only one of the references I read). I suspect it's the same solution everyone finds.)
i Gray >1> xor 011
0 000 000 011 start
1 001 100 111
2 011 101 110
3 010 001 010
4 110 011 000
5 111 111 100
6 101 110 101
7 100 010 001 end
Here's a Python function to do this, and another to reverse it:
def gray_encode_travel( start, end, mask, i ):
travel_bit = start ^ end # ^ means exclusive-or.
modulus = mask + 1 # == 2**nBits
# travel_bit = 2**p, the bit we want to travel.
# Canonical Gray code travels the top bit, 2**(nBits-1).
# So we need to rotate by ( p - (nBits-1) ) == (p + 1) mod nBits.
# We rotate by multiplying and dividing by powers of two:
g = gray_encode( i ) * ( travel_bit * 2 )
return ( ( g | ( g / modulus ) ) & mask ) ^ start
def gray_decode_travel( start, end, mask, g ):
travel_bit = start ^ end
modulus = mask + 1 # == 2**nBits
rg = ( rg ^ start ) * ( modulus / ( travel_bit * 2 ) )
return gray_decode( ( rg | ( rg / modulus ) ) & mask )
. . 5---6 9---10 | | | | 4 7###8 11 # # 3---2 13--12 . | | --0---1...14--15--> ... |Letting small letters stand for child travels and capitals for parent steps, this is the sequence for the 2D walk above:
y Y x X x Y y
This is how our modified Gray code generates the parent steps (capitals) and how we orient the child travels (smalls) in 3D:
z Z y Y y Z x X x Z y Y y Z zNotice that all the odd-numbered (and none of the even) parent steps are along one dimension (Z). That's a property of the Gray code, preserved by our way of modifying it, that makes our child travel pattern (z yy xx yy z) extend to any number of dimensions.
The orientation of the child cube numbered i (0 <= i < 2D) can be calculated directly from the orientation of the parent and i. This table shows the working out of one example, for parent_start = 000 and parent_end = 100 (canonical Gray code), from which a useful pattern can be seen:
i parent(i) child
0 000 000 child_start(0)=parent(0)
001 child_end(0) =parent(1)
^ (flip) v
1 001 000 child_start(1)=parent(0)
010 child_end(1) =parent(3)
^ v
2 011 000 child_start(2)=parent(0)
010 child_end(2) =parent(3)
v ^
3 010 011 child_start(3)=parent(2)
111 child_end(3) =parent(5)
^ v
4 110 011 child_start(4)=parent(2)
111 child_end(4) =parent(5)
^ v
5 111 110 child_start(5)=parent(4)
100 child_end(5) =parent(7)
v ^
6 101 110 child_start(6)=parent(4)
100 child_end(6) =parent(7)
v ^
7 100 101 child_start(7)=parent(6)
100 child_end(7) =parent(7)
The
"^" and "v" markers show how, when a bit flips in the parent walk,
the corresponding bit flips the opposite way, between the end of
the previous child walk and the start of the next. (We're
producing adjacent binary bits here.) Here's the Python function that
calculates the child start and end corners as suggested by the last
two columns of the table:
def child_start_end( parent_start, parent_end, mask, i ): start_i = max( 0, ( i - 1 ) & ~1 ) # next lower even number, or 0 end_i = min( mask, ( i + 1 ) | 1 ) # next higher odd number, or mask child_start = gray_encode_travel( parent_start, parent_end, mask, start_i ) child_end = gray_encode_travel( parent_start, parent_end, mask, end_i ) return child_start, child_end
We decree that the point with index zero is the origin point, and that the first step shall be in the x direction. With our modified Gray code, that means the first level- zero unit cube travels the y dimension. Our child- orientation method always makes the first child of a parent travel the same dimension as the parent's first step. So the level- one parent first steps along y, and travels along z. The level- two parent first steps along z, and so forth. So the orientation of origin- cubes rotates one dimension-- one bit to the right within the D-bit word-- for each level of size. In the following function to handle this, the number of dimensions is nD and the number of levels is nChunks:
def initial_start_end( nChunks, nD ):
# This orients the largest cube so that
# it's start is the origin (0 corner), and
# the first step is along the x axis, regardless of nD and nChunks:
return 0, 2**( ( -nChunks - 1 ) % nD ) # in Python 0 <= a % b < b.
hilbert_pic.pdf | (0K) |
Exploded views of 3D Hilbert walks. |
hilbert_pic.py_txt | (4K) |
Python/pdfgen code that generates hilbert_pic.pdf |
hilbert.py_txt | (8K) |
index <==> Hilbert and support functions. |
hilbert_test.py_txt | (7K) |
Tests hilbert.py functions for 1 to 3 dimensions. |
Makefile | (2K) |
how this stuff is prepared for publishing |
makeindex.php_txt | (18K) |
PHP source for this page (inserts this listing). |
old/ | (dir) |
differences from previous versions |
( x, y, z )are lists that can't be modified once created. They can be passed as arguments, returned from functions, and indexed like lists. They are sometimes implicit in the syntax for multiple assignment or returning multiple values from functions. E.g.
point = ( x, y, z )
point = x, y, z
def f( point ):
x, y, z = point
return x + 1, y + 1, z + 1
point = f( point )
x, y, z = f( point )
x = point[ 0 ]
number_of_dimensions = len( point )
I use tuples for points where I can here just because they
look like points.
"Lists" in Python are actually one-dimensional packed arrays. They are like tuples, but modifiable, so,
a = [ x, y ]
a[ 1 ] = a[ 0 ] + a[ 1]
x, y = a
The expression "[0] * n" means n copies of a list of one zero,
concatenated together-- in other words a list of n zeroes.
In Python, the bitwise operations on ints and longs are:
& and | or ^ xor, exclusive or ~ complementNegative ints in Python, or bitwise complements of positive ints, act as if preceeded by an infinite string of one-bits, and (you might say) vice-versa. So, e.g.,
999999999999 & -2 == 999999999998
~999999999999 == -1000000000000
Unlike in C and Java, Python's '/' with integer arguments is divide-with-floor, and '%' is modulo, so that, e.g.,
-5 / 2 == -3 -5 % 2 == 1
[Butz]
A. R. Butz,
Alternative Algorithm for Hilbert's Space-Filling Curve,
IEEE Trans. Comp., April, 1971, pp 424-426.
[Jaffer] Aubrey Jaffer, Multidimensional Space-Filling Curves
[Lawder]
J.K.Lawder,
Calculation of Mappings Between One and n-dimensional Values
Using the Hilbert Space-filling Curve, Research Report JL1/00,
School of Computer Science and Information Systems,
Birkbeck College, University of London, 2000
[Moore]
D. Moore,
Fast Hilbert Curves in C, without Recursion
[cached]
[Thomas]
S. W. Thomas, "hilbert.c" in the Utah Raster Toolkit circa 1993,
http://web.mit.edu/afs/athena/contrib/urt/src/urt3.1/urt-3.1b.tar.gz
Last change 07 December 2021.
--Steve Witham
Up to my home page.